Introduction
Motivation
We have tools to "explore" the Cardano blockchain, which are useful when you know what you're looking for. We argue that there's a different, complementary use-case which is to "observe" the blockchain and react to particular event patterns.
Oura is a rust-native implementation of a pipeline that connects to the tip of a Cardano node through a combination of Ouroboros mini-protocol (using either a unix socket or tcp bearer), filters the events that match a particular pattern and then submits a succinct, self-contained payload to pluggable observers called "sinks".
Etymology
The name of the tool is inspired by the tail command available in unix-like systems which is used to display the tail end of a text file or piped data. Cardano's consensus protocol name, Ouroboros, is a reference to the ancient symbol depicting a serpent or dragon eating its own tail, which means "tail eating". "Oura" is the ancient greek word for "tail".
Under the Hood
All the heavy lifting required to communicate with the Cardano node is done by the Pallas library, which provides an implementation of the Ouroboros multiplexer and a few of the required mini-protocol state-machines (ChainSync and LocalState in particular).
The data pipeline makes heavy use (maybe a bit too much) of multi-threading and mpsc channels provided by Rust's std::sync library.
Use Cases
CLI to Watch Live Transactions
You can run oura watch <socket> to print TX data into the terminal from the tip of a local or remote node. It can be useful as a debugging tool for developers or if you're just curious to see what's going on in the network (for example, to see airdrops as they happen or oracles posting new information).
As a Bridge to Other Persistence Mechanisms
Similar to the well-known db-sync tool provided by IOHK, Oura can be used as a daemon to follow a node and output the data into a different data storage technology more suited for your final use-case. The main difference with db-sync is that Oura was designed for easy integration with data-streaming pipelines instead of relational databases.
Given its small memory / cpu footprint, Oura can be deployed side-by-side with your Cardano node even in resource-constrained environments, such as Raspberry PIs.
As a Trigger of Custom Actions
Oura running in daemon mode can be configured to use custom filters to pinpoint particular transaction patterns and trigger actions whenever it finds a match. For example: send an email when a particular policy / asset combination appears in a transaction; call an AWS Lambda function when a wallet delegates to a particular pool; send a http-call to a webhook each time a metadata key appears in the TX payload;
As a Library for Custom Scenarios
If the available out-of-the-box features don't satisfy your particular use-case, Oura can be used a library in your Rust project to set up tailor-made pipelines. Each component (sources, filters, sinks, etc) in Oura aims at being self-contained and reusable. For example, custom filters and sinks can be built while reusing the existing sources.
(Experimental) Windows Support
Oura Windows support is currently experimental, Windows build supports only Node-to-Node source with tcp socket bearer.
Installation
Depending on your needs, Oura provides different installation options:
- Binary Release: to use one of our pre-compiled binary releases for the supported platforms.
- From Source: to compile a binary from source code using Rust's toolchain
- Docker: to run the tool from a pre-built docker image
- Kubernetes: to deploy Oura as a resource within a Kubernetes cluster
Binary Releases
Oura can be run as a standalone executable. Follow the instructions for your particular OS / Platform to install a local copy from our Github pre-built releases.
MacOS
Use the following command to download and install Oura's binary release for MacOS:
curl --silent --location https://git.io/JD2iH | \
tar xz -C /tmp && mv /tmp/oura /usr/local/bin
GNU/Linux
Use the following command to download and install Oura's binary release for GNU/Linux:
curl --silent --location https://git.io/JD2ix | \
tar xz -C /tmp && mv /tmp/oura /usr/local/bin
Check the latest release for more binary download options.
From Source
The following instructions show how to build and install Oura from source code.
Pre-requisites
- Rust toolchain
Procedure
git clone git@github.com:txpipe/oura.git
cd oura
cargo install --all-features --path .
Docker
Oura provides already built public Docker images through Github Packages. To execute Oura via Docker, use the following command:
docker run ghcr.io/txpipe/oura:latest
The result of the above command should show Oura's command-line help message.
Entry Point
The entry-point of the image points to Oura executable. You can pass the same command-line arguments that you would pass to the binary release running bare-metal. For example:
docker run -it ghcr.io/txpipe/oura:latest \
watch relays-new.cardano-mainnet.iohk.io:3001 \
--bearer tcp
For more information on available command-line arguments, check the usage section.
Using a Configuration File
The default daemon configuration file for Oura is located in /etc/oura/daemon.toml. To run Oura in daemon mode with a custom configuration file, you need to mount it in the correct location. The following example runs a docker container in background using a configuration file named daemon.toml located in the current folder:
docker run -d -v $(pwd)/daemon.toml:/etc/oura/daemon.toml \
ghcr.io/txpipe/oura:latest daemon
Versioned Images
Images are also tagged with the corresponding version number. It is highly recommended to use a fixed image version in production environments to avoid the effects of new features being included in each release (please remember Oura hasn't reached v1 stability guarantees).
To use a versioned image, replace the latest tag by the desired version with the v prefix. For example, to use version 1.0.0, use the following image:
ghcr.io/txpipe/oura:v1.0.0
Kubernetes
Oura running in daemon mode can be installed can be deployed in Kubernetes cluster, Depending on your needs, we recommend any of the following approaches.
Approach #1: Sidecar Container
Oura can be loaded as a sidecar container in the same pod as your Cardano node. Since containers in a pod share the same file-system layer, it's easy to point Oura to the unix-socket of the node.
In the following example yaml, we show a redacted version of a Cardano node resource defined a s Kubernetes STS. Pay attention on the extra container and to the volume mounts to share the unix socket.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: cardano-node
spec:
# REDACTED: here goes your normal cardano node sts / deployment spec
template:
spec:
# REDACTED: here goes your normal cardano node pod specs
containers:
- name: main
# REDACTED: here goes your normal cardano node container properties
# add a new volume mount to enable the socket to be
# consumed by the 2nd container in the pod (Oura)
volumeMounts:
- mountPath: /opt/cardano/cnode/sockets/node0.socket
name: unix-socket
# add a 2nd container pointing to the _Oura_ image
- name: oura
image: ghcr.io/txpipe/oura:latest
# we mount the same volume that the main container uses as the source
# for the Cardano node unix socket.
volumeMounts:
- mountPath: /opt/cardano/cnode/sockets/node0.socket
name: unix-socket
- mountPath: /etc/oura
name: oura-config
volumes:
# REDACTED: here goes any required volume for you normal cardano node setup
# empty-dir volume to share the unix socket between containers
- name: unix-socket
emptyDir: {}
# a config map resource with Oura's config particular for your requirements
- name: oura-config
configMap:
name: oura-config
Approach #2: Standalone Deployment
Oura can be implemented as a standalone Kubernetes deployment resource. This is useful if your Cardano node is not part of your Kubernetes cluster or if you want to keep your node strictly isolated from the access of a sidecard pod.
Please note that the amount of replicas is set to 1. Oura doesn't have any kind of "coordination" between instances. Adding more than one replica will just create extra pipelines duplicating the same work.
apiVersion: v1
kind: ConfigMap
metadata:
name: oura
data:
daemon.toml: |-
[source]
# REDACTED: here goes your `source` configuration options
[[filters]]
# REDACTED: here goes your `filters` configuration options
[sink]
# REDACTED: here goes your `sink` configuration options
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: oura
labels:
app: oura
spec:
replicas: 1
selector:
matchLabels:
app: oura
template:
metadata:
labels:
app: oura
spec:
containers:
- name: main
image: ghcr.io/txpipe/oura:latest
env:
- name: "RUST_LOG"
value: "info"
resources:
requests:
memory: 50Mi
cpu: 50m
limits:
memory: 200Mi
cpu: 200m
args:
- "daemon"
volumeMounts:
- mountPath: /etc/oura
name: config
volumes:
- name: config
configMap:
name: oura
Usage
Oura provides three different execution modes:
- Daemon: a fully-configurable pipeline that runs in the background. Sources, filters and sinks can be combined to fulfil particular use-cases.
- Watch: to watch live block events from a node directly in the terminal. It is meant for humans, it uses colors and throttling to facilitate reading.
- Dump: to dump live block events from a node into rotation log files or stdout. It uses JSONL format for persistence of the events.
Watch Mode
The watch mode provides a quick way to tail the latest events from the blockchain. It connects directly to a Cardano node using either node-to-client or node-to-node protocols. The output is sent into the terminal in a human-readable fashion.
The output is colorized by type of event and dynamically truncated to fit the width of the terminal. The speed of the output lines is throttled to facilitate visual inspection of each even, otherwise, all events for a block would be output simultaneously.
Usage
To start Oura in watch mode, use the following command from your terminal:
oura watch [OPTIONS] <socket>
<socket>: this a required argument that specifies how to connect to the cardano node. It can either be a tcp address (<host>:<port>syntax) or a file path pointing to the location of the unix socket.
Options
--bearer <bearer>: an option that specifies the type of bearer to use. Possible values aretcpandunix. If omitted, the valueunixis used as default.--magic <magic>: the magic number of the network you're connecting to. Possible values aremainnet,testnet,preview,preprodor a numeric value. If omitted, the valuemainnetis used as default.--mode <mode>: an option to force the which set of mini-protocols to use when connecting to the Cardano node. Possible values:nodeandclient. If omitted, Oura will infer the standard protocols for the specified bearer.--since <slot>,<hash>: an option to specify from which point in the chain Oura should start reading from. The point is referenced by passing the slot of the block followed by a comma and the hash of the block (<slot>,<hash>). If omitted, Oura will start reading from the tail (tip) of the node.--wrap: indicates that long output text should break and continue in the following line. If omitted, lines will be truncated to fit in the available terminal width.
Examples
Watch Live Data From A Remote Relay Node
oura watch relays-new.cardano-mainnet.iohk.io:3001 --bearer tcp
Watch Live Data From A Local Node Via Unix Socket
oura watch /opt/cardano/cnode/sockets/node0.socket --bearer unix
Watch Live Data From The Tip Of A Local Testnet Node
oura watch /opt/cardano/cnode/sockets/node0.socket --bearer unix --magic testnet
Watch Data Starting At A Particular Block
oura watch relays-new.cardano-mainnet.iohk.io:3001 \
--bearer tcp \
--since 49159253,d034a2d0e4c3076f57368ed59319010c265718f0923057f8ff914a3b6bfd1314
Watch Live Data From the "Preview" testnet
oura watch preview-node.world.dev.cardano.org:30002 --bearer tcp --magic preview
Watch Live Data From the "Pre-Production" testnet
oura watch preprod-node.world.dev.cardano.org:30000 --bearer tcp --magic preprod
Daemon Mode
Oura's daemon mode processes data in the background, without any live output. This mode is used in scenarios where you need to continuously bridge blockchain data with other persistence mechanisms or to trigger an automated process in response to a particular event pattern.
Start Daemon Mode
To start Oura in daemon mode, use the following command:
oura daemon
Available options:
--config: path of a custom toml configuration file to use. If not specified, configuration will be loaded from/etc/oura/daemon.toml.--cursor: a custom point in the chain to use as starting point. Expects format:slot,hex-hash. If not specified, it will look for the cursor section available via toml configuration or fallback to the intersect options of the source stage.
Example of starting daemon mode with default config file:
# config will be loaded from /etc/oura/daemon.toml
oura daemon
Example of starting daemon mode with a custom config file at my_config.toml:
oura daemon --config my_config.toml
Example of starting daemon mode specifying a particular cursor:
oura daemon --cursor 56134714,2d2a5503c16671ac7d5296f8e6bfeee050b2c2900a7d8c97b36c434667eb99d9
Configuration
The configuration file needs to specify the source, filters and sink to use in a particular pipeline. The following toml represent the typical skeleton of an Oura config file:
[source]
type = "X" # the type of source to use
# custom config fields for this source type
foo = "abc"
bar = "xyz"
[[filters]]
type = "Y" # the type of filter to use
# custom config fields for this filter type
foo = "123"
bar = "789"
[sink]
# the type of sink to use
type = "Z"
# custom config fields for this sink type
foo = "123"
bar = "789"
# optional cursor settings, remove seaction to disable feature
[cursor]
type = "File"
path = "/var/oura/cursor"
The source section
This section specifies the origin of the data. The special type field must always be present and containing a value matching any of the available built-in sources. The rest of the fields in the section will depend on the selected type. See the sources section for a list of available options and their corresponding config values.
The filters section
This section specifies a collection of filters that are applied in sequence to each event. The special type field must always be present and containing a value matching any of the available built-in filters. Notice that this section of the config is an array, allowing multiple filter sections per config file. See the filters section for a list of available options and their corresponding config values.
The sink section
This section specifies the destination of the data. The special type field must always be present and containing a value matching any of the available built-in sinks. The rest of the fields in the section will depend on the selected type. See the sinks section for a list of available options.
The cursor section
This section specifies how to configure the cursor feature. A cursor is a reference of the current position of the pipeline. If the pipeline needs to restart for whatever reason, and a cursor is available, the pipeline will start reading from that point in the chain. Removing the section from the config will disable the cursor feature.
Full Example
Here's an example configuration file that uses a Node-to-Node source and output the events into a Kafka sink:
[source]
type = "N2N"
address = ["Tcp", "relays-new.cardano-mainnet.iohk.io:3001"]
magic = "mainnet"
[[filters]]
type = "Fingerprint"
[[filters]]
type = "Selection"
predicate = "variant_in"
argument = ["Block", "Transaction"]
[sink]
type = "Kafka"
brokers = ["127.0.0.1:53147"]
topic = "testnet"
Dump Mode
The dump mode provides a quick way to tail the latest events from the blockchain and outputs raw data into stdout or the file system. It connects directly to a Cardano node using either node-to-client or node-to-node protocols. The output is formatted using JSONL (json, one-line per event). This command is intended mainly as quick persistence mechanism of blockchain data, such as keeping a log of blocks / transactions. It can also be used for "piping" stdout into other shell commands.
If an output path is specified, data will be saved as a set of rotation logs files. Each log file will contain a max of ~50mb. A total of 200 files will be stored before starting to delete the older ones. Gzip is used to compress old files as they are rotated.
For real-time, human-inspection of the events, use the watch command.
Usage
To start Oura in dump mode, use the following command from your shell:
oura dump [OPTIONS] <socket>
<socket>: this a required argument that specifies how to connect to the cardano node. It can either be a tcp address (<host>:<port>syntax) or a file path pointing to the location of the unix socket.
Options
--bearer <bearer>: an option that specifies the type of bearer to use. Possible values aretcpandunix. If omitted, the valueunixis used as default.--magic <magic>: the magic number of the network you're connecting to. Possible values aremainnet,testnetor a numeric value. If omitted, the valuemainnetis used as default.--mode <mode>: an option to force the which set of mini-protocols to use when connecting to the Cardano node. Possible values:nodeandclient. If omitted, Oura will infer the standard protocols for the specified bearer.--since <slot>,<hash>: an option to specify from which point in the chain Oura should start reading from. The point is referenced by passing the slot of the block followed by a comma and the hash of the block (<slot>,<hash>). If omitted, Oura will start reading from the tail (tip) of the node.--output <path-like>: an option to specify an output file prefix for storing the log files. Logs are rotated, so a timestamp will be added as a suffix to the final filename. If omitted, data will be sent to stdout.
Examples
Dump Data From A Remote Relay Node into Stdout
oura dump relays-new.cardano-mainnet.iohk.io:3001 --bearer tcp
Dump Data From A Remote Relay Node into Rotating Files
oura dump relays-new.cardano-mainnet.iohk.io:3001 --bearer tcp --output ./mainnet-logs
Pipe Data From A Remote Relay Node into a new Shell Command
oura dump relays-new.cardano-mainnet.iohk.io:3001 --bearer tcp | grep block
Library
Coming Soon!
Filters
Filters are intermediate steps in the pipeline that process events as they travel from sources to sinks. They might serve different pourposes, such as: selecting relevant events, enriching event data, transforming data representation, etc.
Built-in Filters
These are the existing filters that are included as part the main Oura codebase:
- Fingerprint: a filter that adds a (probably) unique identifier (fingerprint) to each event.
- Selection: a filter that evaluates different built-in predicates to decide which events should go through the pipeline.
New filters are being developed, information will be added in this documentation to reflect the updated list. Contributions and feature request are welcome in our Github Repo.
Fingerprint Filter
A filter that computes a (probably) unique identifier for each event and appends it as part of the data passed forward.
Dealing with duplicated records is a common problem in data pipelines. A common workaround is to use identifiers based on the hash of the data for each record. In this way, a duplicated record would yield the same hash, allowing the storage engine to discard the extra instance.
The fingerprint filter uses the non-cryptographic hash algorithm murmur3 to compute an id for each Oura event with a very low collision level. We use a non-cryptographic hash because they are faster to compute and non of the cryptographic properties are required for this use-case.
When enabled, this filter will set the fingerprint property of the Event data structure passed through each stage of the pipeline. Sinks at the end of the process might leverage this value as primary key of the corresponding storage mechanism.
Configuration
Adding the following section to the daemon config file will enable the filter as part of the pipeline:
[[filters]]
type = "Fingerprint"
Section: filter
type: the literal valueFingerprint.
Selection Filter
A filter that evaluates a set of configurable predicates against each event in the pipeline to decide which records should be sent to the following stage.
Not every use-case requires each and every event to be processed. For example, a pipeline interested in creating a 'metadata' search engine might not care about transaction outputs. With a similar logic, a pipeline aggregating transaction amounts might not care about metadata. The selection filter provides a way to optimize the pipeline so that only relevant events are processed.
The filter works by evaluating a predicate against each event. If the predicate returns true, then the event will continue down the pipeline. If the predicate evalutes to false, the event will be dopped. We currently provide some common built-in predicate to facilitate common use-cases (eg: matching event type, matching policy id, matching a metadata key, etc.). We also provide some 'connecting' predicates like all_of, any_of, and not which can be used to create complex conditions by composing other predicates.
Configuration
Adding the following section to the daemon config file will enable the filter as part of the pipeline:
[[filters]]
type = "Selection"
[filters.check]
predicate = "<predicate kind>"
argument = <predicate argument>
Section: filters
type: the literal valueSelection.
Section filters.check
predicate: the key of the predicate to use for the evaluation. See the list of available predicates for possible values.argument: a polimorphic argument that specializes the behavior of the predicate in some way.
Available Predicates
variant_in (string[]): This predicate will yield true when the variant of the event matches any of the items in the argument array.variant_not_in (string[]): This predicate will yield true when the variant of the event doesn't match any of the items in the argument array.policy_equals (string): This predicate will yield true when the policy of a mint or output asset matches the value in the argument.asset_equals (string): This predicate will yield true when the policy of a mint or output asset matches the value in the argument.metadata_label_equals (string): This predicate will yield true when the root label of a metadata entry matches the value in the argument.metadata_any_sub_label_equals (string): This predicate will yield true when at least one of the sub labels in a metadata entry matches the value in the argument.not (predicate): This predicate will yield true when the predicate in the arguments yields false.any_of (predicate[]): This predicate will yield true when any of the predicates in the argument yields true.all_of (predicate[]): This predicate will yield true when all of the predicates in the argument yields true.
Examples
Allowing only block and transaction events to pass:
[[filters]]
type = "Selection"
[filters.check]
predicate = "variant_in"
argument = ["Block", "Transaction"]
Using the not predicate to allow all events except the variant Transaction:
[[filters]]
type = "Selection"
[filters.check]
predicate = "not"
[filters.check.argument]
predicate = "variant_in"
argument = ["Transaction"]
Using the any_of predicate to filter events presenting any of two different policies (Boolean "or"):
[filters.check]
predicate = "any_of"
[[filters.check.argument]]
predicate = "policy_equals"
argument = "4bf184e01e0f163296ab253edd60774e2d34367d0e7b6cbc689b567d"
[[filters.check.argument]]
predicate = "policy_equals"
argument = "a5bb0e5bb275a573d744a021f9b3bff73595468e002755b447e01559"
Using the all_of predicate to filter only "asset" events presenting a particular policy (Boolean "and") :
[filters.check]
predicate = "all_of"
[[filters.check.argument]]
predicate = "variant_in"
argument = ["OutputAsset"]
[[filters.check.argument]]
predicate = "policy_equals"
argument = "a5bb0e5bb275a573d744a021f9b3bff73595468e002755b447e01559"
Sources
Sources represent the "origin" of the events processed by Oura. Any compatible source is responsible for feeding blockchain data into Oura's pipeline for further processing.
Built-in Sources
These are the currently available sources included as part the main Oura codebase:
- N2N: an Ouroboros agent that connects to a Cardano node using node-2-node protocols
- N2C: an Ouroboros agent that connects to a Cardano node using node-2-client protocols
New source are being developed, information will be added in this documentation to reflect the updated list. Contributions and feature request are welcome in our Github Repo.
Node-to-Node
The Node-to-Node (N2N) source uses Ouroboros mini-protocols to connect to a local or remote Cardano node through a tcp socket bearer and fetches block data using the ChainSync mini-protocol instantiated to "headers only" and the BlockFetch mini-protocol for retrieval of the actual block payload.
Configuration
The following snippet shows an example of how to set up a typical N2N source:
[source]
type = "N2N"
address = ["Tcp", "<hostname:port>"]
magic = <network magic>
[source.intersect]
type = <intersect strategy>
value = <intersect argument>
[source.mapper]
include_block_end_events = <bool>
include_transaction_details = <bool>
include_transaction_end_events = <bool>
include_block_cbor = <bool>
Section source:
type: this field must be set to the literal valueN2Naddress: a tuple describing the location of the tcp endpoint It must be specified as a string with hostname and port number.magic: the magic of the network that the node is running (mainnet,testnetor a custom numeric value)sinceintersect) the point in the chain where reading of events should start from. It must be specified as a tuple of slot (integer) and block hash (hex string)
Section source.intersect
This section provides advanced options for instructing Oura from which point in the chain to start reading from. Read the intersect options documentation for detailed information.
Section source.mapper
This section provides a way to opt-in into advances behaviour of how the raw chain data is mapped into Oura events. Read the mapper options documentation for detailed information.
Examples
Connecting to a remote Cardano node in mainnet through tcp sockets:
[source]
type = "N2N"
address = ["Tcp", "relays-new.cardano-mainnet.iohk.io:3001"]
magic = "mainnet"
Connecting to a remote Cardano node in testnet through tcp sockets:
[source]
type = "N2N"
address = ["Tcp", "relays-new.cardano-mainnet.iohk.io:3001"]
magic = "testnet"
Start reading from a particular point in the chain:
[source]
type = "N2C"
address = ["Tcp", "relays-new.cardano-mainnet.iohk.io:3001"]
magic = "mainnet"
[source.intersect]
type = "Point"
value = [48896539, "5d1f1b6149b9e80e0ff44f442e0cab0b36437bb92eacf987384be479d4282357"]
Include all details inside the transaction events:
[source]
type = "N2N"
address = ["Tcp", "relays-new.cardano-mainnet.iohk.io:3001"]
magic = "mainnet"
[source.mapper]
include_transaction_details = true
include_block_cbor = true
Node-to-Client
The Node-to-Client (N2C) source uses Ouroboros mini-protocols to connect to a local Cardano node through a unix socket bearer and fetches block data using the ChainSync mini-protocol instantiated to "full blocks".
Configuration
The following snippet shows an example of how to set up a typical N2C source:
[source]
type = "N2C"
address = ["Unix", "<socket location>"]
magic = <network magic>
[source.intersect]
type = <intersect strategy>
value = <intersect argument>
[source.mapper]
include_block_end_events = <bool>
include_transaction_details = <bool>
include_transaction_end_events = <bool>
include_block_cbor = <bool>
Section source:
type: this field must be set to the literal valueN2Caddress: a tuple describing the location of the socketmagic: the magic of the network that the node is running (mainnet,testnetor a custom numeric value)sinceintersect) the point in the chain where reading of events should start from. It must be specified as a tuple of slot (integer) and block hash (hex string)
Section source.intersect
This section provides advanced options for instructing Oura from which point in the chain to start reading from. Read the intersect options documentation for detailed information.
Section source.mapper
This section provides a way to opt-in into advances behaviour of how the raw chain data is mapped into Oura events. Read the mapper options documentation for detailed information.
Examples
Connecting to a local Cardano node in mainnet through unix sockets:
[source]
type = "N2C"
address = ["Unix", "/opt/cardano/cnode/sockets/node0.socket"]
magic = "mainnet"
Connecting to a local Cardano node in testnet through unix sockets:
[source]
type = "N2C"
address = ["Unix", "/opt/cardano/cnode/sockets/node0.socket"]
magic = "testnet"
Start reading from a particular point in the chain:
[source]
type = "N2C"
address = ["Unix", "/opt/cardano/cnode/sockets/node0.socket"]
magic = "mainnet"
[source.intersect]
type = "Point"
value = [48896539, "5d1f1b6149b9e80e0ff44f442e0cab0b36437bb92eacf987384be479d4282357"]
Include all details inside the transaction events:
[source]
type = "N2C"
address = ["Unix", "/opt/cardano/cnode/sockets/node0.socket"]
magic = "mainnet"
[source.mapper]
include_transaction_details = true
include_block_cbor = true
Sinks
Sinks are the "destination" of the events processed by Oura. They are the concrete link between the internal representation of the data records and the corresponding external service interested in the data. Typical sinks include: database engines, stream-processing engines, web API calls and FaaS solutions.
Built-in Sinks
These are the existing sinks that are included as part the main Oura codebase:
- Terminal: a sink that outputs events into stdout with fancy coloring
- Kakfa: a sink that sends each event into a Kafka topic
- Elasticsearch: a sink that writes events into an Elasticsearch index or data stream.
- Webhook: a sink that outputs each event as an HTTP call to a remote endpoint.
- Logs: a sink that saves events to the file system using JSONL text files.
- AWS SQS: a sink that sends each event as message to an AWS SQS queue.
- AWS Lamda: a sink that invokes an AWS Lambda function for each event.
- AWS S3: a sink that saves the CBOR content of the blocks as an AWS S3 object.
- Redis Streams: a sink that sends each event into a Redis stream.
New sinks are being developed, information will be added in this documentation to reflect the updated list. Contributions and feature request are welcome in our Github Repo.
Terminal
A sink that outputs each event into the terminal through stdout using fancy coloring 💅.
Configuration
[sink]
type = "Terminal"
throttle_min_span_millis = 500
wrap = true
type(required): the literal valueTerminal.throttle_min_span_millis(optional, default =500): the amount of time (milliseconds) to wait between printing each event into the console. This is used to facilitate the reading for human following the output.wrap(optional, default =false): a true value indicates that long output text should break and continue in the following line. If false, lines will be truncated to fit in the available terminal width.
Kafka
A sink that implements a Kafka producer. Each event is json-encoded and sent as a message to a single Kafka topic.
Configuration
[sink]
type = "Kafka"
brokers = ["kafka-broker-0:9092"]
topic = "cardano-events"
type: the literal valueKafka.brokers: indicates the location of the Kafka brokers within the network. Several hostname:port pairs can be added to the array for a "cluster" scenario.topicthis field indicates which Kafka topic to use to send the outbound messages.
Elasticsearch
A sink that outputs events into an Elasticsearch server. Each event is json-encoded and sent as a message to an index or data stream.
Configuration
[sink]
type = "Elastic"
url = "https://localhost:9200"
index = "oura.sink.v0.mainnet"
[sink.credentials]
type = "Basic"
username = "oura123"
password = "my very secret stuff"
Section: sink
type: the literal valueElastic.url: the location of the Elasticsearch's APIindex: the name of the index (or data stream) to store the event documentsidempotency(optional): flag that if enabled will force idempotent calls to ES (to avoid duplicates)retry_policy(optional): controls the policy to retry failed requests (see retry policy)
Section: sink.credentials
This section configures the auth mechanism against Elasticsearch. You can remove the whole section from the configuration if you want to skip authentication altogether (maybe private cluster without auth?).
We currently only implement basic auth, other mechanisms will be implemented at some point.
type: the mechanism to use for authentication, onlyBasicis currently implementedusername: username of the user with access to Elasticsearchpassword: password of the user with access to Elasticsearch
Idempotency
In services and API calls, idempotency refers to a property of the system where the execution of multiple "equivalent" requests have the same effect as a single request. In other words, "idempotent" calls can be triggered multiple times without problem.
In our Elasticsearch sink, when the idempotency flag is enabled, each document sent to the index will specify a particular content-based ID: the fingerprint of the event. If Oura restarts without having a cursor or if the same block is processed for any reason, repeated events will present the same ID and Elasticsearch will reject them and Oura will continue with the following event. This mechanism provides a strong guarantee that our index won't contain duplicate data.
If the flag is disabled, each document will be generated using a random ID, ensuring that it will be indexed regardless.
Webhook
A sink that outputs each event as an HTTP call to a remote endpoint. Each event is json-encoded and sent as the body of a request using POST method.
The sink expect a 200 reponse code for each HTTP call. If found, the process will continue with the next message. If an error occurs (either at the tcp or http level), the sink will apply the corresponding retry logic as specified in the configuration.
Configuration
[sink]
type = "Webhook"
url = "https://endpoint:5000/events"
authorization = "user:pass"
timeout = 30000
error_policy = "Continue"
[sink.retry_policy]
max_retries = 30
backoff_unit = 5000
backoff_factor = 2
max_backoff = 100000
[sink.headers]
extra_header_1 = "abc"
extra_header_2 = "123"
Section: sink
type: the literal valueWebhook.url: url of your remote endpoint (needs to accept POST method)authorization(optional): value to add as the 'Authorization' HTTP headerheaders(optional): key-value map of extra headers to pass in each HTTP callallow_invalid_certs(optional): a flag to skip TLS cert validation (usually for self-signed certs).timeout(optional): the timeout value for the HTTP response in milliseconds. Default value is30000.error_policy(optional): eitherContinueorExit. Default value isExit.retry_policy(optional): controls the policy to retry failed requests (see retry policy)
Logs
A sink that saves events into the file system. Each event is json-encoded and appended to the of a text file. Files are rotated once they reach a certain size. Optionally, old files can be automatically compressed once they have rotated.
Configuration
Example sink section config
[sink]
type = "Logs"
output_path = "/var/oura/mainnet"
output_format = "JSONL"
max_bytes_per_file = 1_000_000
max_total_files = 10
compress_files = true
Section: sink
type: the literal valueLogs.output_path: the path-like prefix for the output log filesoutput_format(optional): specified the type of syntax to use for the serialization of the events. Only available option at the moment isJSONL(json + line break)max_bytes_per_file(optional): the max amount of bytes to add in a file before rotating itmax_total_files(optional): the max amount of files to keep in the file system before start deleting the old onescompress_files(optional): a boolean indicating if the rotated files should be compressed.
AWS SQS
A sink that sends each event as a message to an AWS SQS queue. Each event is json-encoded and sent to a configurable SQS queue using AWS API endpoints.
The sink will process each incoming event in sequence and submit the corresponding SendMessage request to the SQS API. Once the queue acknowledges reception of the message, the sink will advance and continue with the following event.
The sink support both FIFO and Standard queues. The sink configuration will determine which logic to apply. In case of FIFO, the group id is determined by an explicit configuration value and the message id is defined by the fingerprint value of the event (Fingerprint filter needs to be enabled).
The sink uses AWS SDK's built-in retry logic which can be configured at the sink level. Authentication against AWS is built-in in the SDK library and follows the common chain of providers (env vars, ~/.aws, etc).
Configuration
[sink]
type = "AwsSqs"
region = "us-west-2"
queue_url = "https://sqs.us-west-2.amazonaws.com/xxxxxx/my-queue"
fifo = true
group_id = "my_group"
max_retries = 5
Section: sink
type: the literal valueAwsSqs.region: The AWS region where the queue is located.queue_url: The SQS queue URL provided by AWS (not to be confused with the ARN).fifo: A flag to determine if the queue is of type FIFO.group_id: A fixed group id to be used when sending messages to a FIFO queue.max_retries: The max number of send retries before exiting the pipeline with an error.
AWS Credentials
The sink needs valid AWS credentials to interact with the cloud service. The majority of the SDKs and libraries that interact with AWS follow the same approach to access these credentials from a chain of possible providers:
- Credentials stored as the environment variables AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY.
- A Web Identity Token credentials from the environment or container (including EKS)
- ECS credentials (IAM roles for tasks)
- As entries in the credentials file in the .aws directory in your home directory (~/.aws/)
- From the EC2 Instance Metadata Service (IAM Roles attached to an instance)
Oura, by mean of the Rust AWS SDK lib, will honor the above chain of providers. Use any of the above that fits your particular scenario. Please refer to AWS' documentation for more detail.
FIFO vs Standard Queues
Oura processes messages maintaining the sequence of the blocks and respecting the order of the transactions within the block. An AWS SQS FIFO queue provides the consumer with a guarantee that the order in which messages are consumed matches the order in which they were sent.
Connecting Oura with a FIFO queue would provide the consumer with the guarantee that the events received follow the same order as they appeared in the blockchain. This might be useful, for example, in scenarios where the processing of an event requires a reference of a previous state of the chain.
Please note that rollback events might happen upstream, at the blockchain level, which need to be handled by the consumer to unwind any side-effects of the processing of the newly orphaned blocks. This problem can be mitigated by using Oura's rollback buffer feature.
If each event can be processed in isolation, if the process is idempotent or if the order doesn't affect the outcome, the recommended approach is to use a Standard queue which provides "at least once" processing guarantees, relaxing the constraints and improving the overall performance.
Payload Size Limitation
AWS SQS service has a 256kb payload size limit. This is more than enough for individual events, but it might be too little for pipelines where the include_cbor_hex option is enabled. If your goal of your pipeline is to access the raw CBOR content, we recommend taking a look at the AWS S3 Sink that provides a direct way for storing CBOR block in an S3 bucket.
AWS Lambda
A sink that invokes an AWS Lambda function for each received event. Each event is json-encoded and sent to a configurable function using AWS API endpoints.
The sink will process each incoming event in sequence, invoke the specified function and wait for the response.
A retry mechanism is available for failures to dispatch the call, but not for failures within the execution of the function. Regardless of the success or not of the function, the sink will advance and continue with the following event.
Authentication against AWS is built-in in the SDK library and follows the common chain of providers (env vars, ~/.aws, etc).
Configuration
[sink]
type = "AwsLambda"
region = "us-west-2"
function_name = "arn:aws:lambda:us-west-2:xxxxx:function:my-func"
max_retries = 5
Section: sink
type: the literal valueAwsLambda.region: The AWS region where the function is located.function_name: The ARN of the function we wish to invoke.max_retries: The max number of send retries before exiting the pipeline with an error.
AWS Credentials
The sink needs valid AWS credentials to interact with the cloud service. The majority of the SDKs and libraries that interact with AWS follow the same approach to access these credentials from a chain of possible providers:
- Credentials stored as the environment variables AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY.
- A Web Identity Token credentials from the environment or container (including EKS)
- ECS credentials (IAM roles for tasks)
- As entries in the credentials file in the .aws directory in your home directory (~/.aws/)
- From the EC2 Instance Metadata Service (IAM Roles attached to an instance)
Oura, by mean of the Rust AWS SDK lib, will honor the above chain of providers. Use any of the above that fits your particular scenario. Please refer to AWS' documentation for more detail.
AWS S3
A sink that saves the CBOR content of the blocks as S3 object.
The sink will process each incoming event in sequence and select only the events of type Block. The CBOR content of the block will be extracted and saves as an S3 object in a configurable bucket in either hex or binary encoding.
A configurable option allows the user to decide how to name the object using values from the block header (such as epoch, slot, hash, etc). The properties of the block will be saved as metadata of the S3 Object for later identification (eg: block number, hash, slot, etc).
The sink uses AWS SDK's built-in retry logic which can be configured at the sink level. Authentication against AWS is built-in in the SDK library and follows the common chain of providers (env vars, ~/.aws, etc).
Configuration
[sink]
type = "AwsS3"
region = "us-west-2"
bucket = "my-bucket"
prefix = "mainnet/"
naming = "SlotHash"
content = "Cbor"
max_retries = 5
Section: sink
type: the literal valueAwsS3.function_name: The ARN of the function we wish to invoke.region: The AWS region where the bucket is located.bucket: The name of the bucket to store the blocks.prefix: A prefix to prepend on each object's key.naming: One of the available naming conventions (see section below)content: EitherCborfor binary encoding orCborHexfor plain text hex representation of the CBORmax_retries: The max number of send retries before exiting the pipeline with an error.
IMPORTANT: For this sink to work correctly, the include_block_cbor option should be enabled in the source sink configuration (see mapper options).
Naming Convention
S3 Buckets allow the user to query by object prefix. It's important to use a naming convention that is compatible with the types of filters that the consumer intends to use. This sink provides the following options:
Hash: formats the key using"{hash}"SlotHash: formats the key using"{slot}.{hash}"BlockHash: formats the key using"{block_num}.{hash}"EpochHash: formats the key using"{epoch}.{hash}"EpochSlotHash: formats the key using"{epoch}.{slot}.{hash}"EpochBlockHash: formats the key using"{epoch}.{block_num}.{hash}"
Content Encoding
The sink provides two options for encoding the content of the object:
Cbor: the S3 object will contain the raw, unmodified CBOR value in binary format. The content type of the object in this case will be "application/cbor".CborHex: the S3 object will contain the CBOR payload of the block encoded as a hex string. The content type of the object in this case will be "text/plain".
Metadata
The sink uses the data from the block event to populate metadata fields of the S3 object for easier identification of the block once persisted:
eraissuer_vkeytx_countslothashnumberprevious_hash
Please note that S3 doesn't allow filtering by metadata. For efficient filter, the only option available is to use the prefix of the key.
AWS Credentials
The sink needs valid AWS credentials to interact with the cloud service. The majority of the SDKs and libraries that interact with AWS follow the same approach to access these credentials from a chain of possible providers:
- Credentials stored as the environment variables AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY.
- A Web Identity Token credentials from the environment or container (including EKS)
- ECS credentials (IAM roles for tasks)
- As entries in the credentials file in the .aws directory in your home directory (~/.aws/)
- From the EC2 Instance Metadata Service (IAM Roles attached to an instance)
Oura, by mean of the Rust AWS SDK lib, will honor the above chain of providers. Use any of the above that fits your particular scenario. Please refer to AWS' documentation for more detail.
Google Cloud PubSub
A sink that sends each event as a message to a PubSub topic. Each event is json-encoded and sent to a configurable PubSub topic.
Configuration
[sink]
type = "GcpPubSub"
topic = "test"
[sink.retry_policy]
max_retries = 30
backoff_unit = 5000
backoff_factor = 2
max_backoff = 100000
Section: sink
type: the literal valueGcpPubSub.topic: the short name of the topic to send message to.error_policy(optional): eitherContinueorExit. Default value isExit.- retry_policy
GCP Authentication
The GCP authentication process relies on the following conventions:
- If the
GOOGLE_APPLICATION_CREDENTIALSenvironmental variable is specified, the value will be used as the file path to retrieve the JSON file with the credentials. - If the server is running on GCP, the credentials will be retrieved from the metadata server.
Redis Streams
A sink that outputs events into Redis Stream.
Redis Streams works as an append-only log where multiple consumers can read from the same queue while keeping independent offsets (as opposed to a PubSub topic where one subscriber affect the other). You can learn more about the Streams feature in the official Redis Documentation.
This sink will process incoming events and send a JSON-encoded message of the payload for each one using the XADD command. The Redis instance can be local or remote.
Configuration
Example configuration that sends all events into a single stream named mystream of a Redis instance running in port 6379 of the localhost.
[sink]
type = "Redis"
redis_server = "redis://localhost:6379"
stream_name = "mystream"
Example configuration that sends events into different streams (named by the type of event) of a Redis instance running in port 6379 of the localhost.
[sink]
type = "Redis"
redis_server = "redis://localhost:6379"
stream_strategy = "ByEventType"
Section: sink
type: the literal valueRedis.redis_server: the redis server in the formatredis://[<username>][:<password>]@<hostname>[:port][/<db>]stream_name: the name of the redis stream for StreamStrategyNone, default is "oura" if not specifiedstream_strategy:NoneorByEventType
Conventions
It is possible to send all Event to a single stream or create multiple streams, one for each event type. By appling the selection filter it is possible to define the streams which should be created.
The sink uses the default Redis convention to define the unique entry ID for each message sent to the stream ( <millisecondsTime>-<sequenceNumber>).
Messages in Redis Streams are required to be hashes (maps between the string fields and the string values). This sink will serialize the event into a single-entry map with the following parts:
key: the fingerprint value if available, or the event type name.value: the json-encoded payload of the event.
Reference
Data Dictionary
Oura follows a Cardano chain and outputs events. Each event contains data about itself and about the context in which it occurred.
A consumer aggregating a sequence of multiple events will notice redundant / duplicated data. For example, the "block number" value will appear repeated in the context of every event of the same block. This behavior is intended, making each event a self-contained record is an architectural decision. We favor "consumption ergonomics" over "data normalization".
Available Events
The following list represent the already implemented events. These data structures are represented as an enum at the code level.
RollBack Event
Data on chain rollback(The result of the local node switching to the consensus chains).
| Name | DataType | Description |
|---|---|---|
| block_slot | u64 | Slot of the rolled back block. |
| block_hash | String | Hash of the rolled back block. |
Block Event
Data on an issued block.
| Name | DataType | Description |
|---|---|---|
| body_size | usize | Size of the block. |
| issuer_vkey | String | Block issuer Public verification key. |
Context
| Name | DataType | Description |
|---|---|---|
| block_number | Option<u64> | Height of block from genesis. |
| slot | Option<u64> | Current slot. |
Transaction Event
Data on a transaction.
| Name | DataType | Description |
|---|---|---|
| fee | u64 | Transaction fees in lovelace. |
| ttl | Option<u64> | Transaction time to live. |
| validity_interval_start | Option<u64> | Start of transaction validity interval |
| network_id | Option<u32> | Network ID. |
Context
| Name | DataType | Description |
|---|---|---|
| block_number | Option<u64> | Height of block from genesis. |
| slot | Option<u64> | Current slot. |
| tx_idx | Option<usize> | Transaction Index. |
| tx_hash | Option<String> | Transaction hash. |
TxInput Event
Data on a transaction input.
| Name | DataType | Description |
|---|---|---|
| tx_id | String | Transaction ID. |
| index | u64 | Index of input in transaction inputs. |
Context
| Name | DataType | Description |
|---|---|---|
| block_number | Option<u64> | Height of block from genesis. |
| slot | Option<u64> | Current slot. |
| tx_idx | Option<usize> | Transaction Index. |
| tx_hash | Option<String> | Transaction hash. |
| input_idx | Option<usize> | Input ID. |
TxOutput Event
Data on a transaction output (UTXO).
| Name | DataType | Description |
|---|---|---|
| address | String | Address of UTXO. |
| amount | u64 | Amount of lovelace in UTXO. |
Context
| Name | DataType | Description |
|---|---|---|
| block_number | Option<u64> | Height of block from genesis. |
| slot | Option<u64> | Current slot. |
| tx_idx | Option<usize> | Transaction Index. |
| tx_hash | Option<String> | Transaction hash. |
| output_idx | Option<usize> | Output ID. |
OutputAsset Event
Data on a non-ADA asset in a UTXO.
| Name | DataType | Description |
|---|---|---|
| policy | String | Minting policy of asset. |
| asset | String | Asset ID. |
| amount | u64 | Amount of asset. |
Context
| Name | DataType | Description |
|---|---|---|
| block_number | Option<u64> | Height of block from genesis. |
| slot | Option<u64> | Current slot. |
| tx_idx | Option<usize> | Transaction Index. |
| tx_hash | Option<String> | Transaction hash. |
| output_idx | Option<usize> | Output ID. |
Metadata Event
| Name | DataType | Description |
|---|---|---|
| key | String | .... |
| subkey | Option<String> | .... |
| value | Option<String> | .... |
Context
| Name | DataType | Description |
|---|---|---|
| block_number | Option<u64> | Height of block from genesis. |
| slot | Option<u64> | Current slot. |
| tx_idx | Option<usize> | Transaction Index. |
| tx_hash | Option<String> | Transaction hash. |
Mint Event
Data on the minting of a non-ADA asset.
| Name | DataType | Description |
|---|---|---|
| policy | String | Minting policy of asset. |
| asset | String | Asset ID. |
| quantity | i64 | Quantity of asset minted. |
Context
| Name | DataType | Description |
|---|---|---|
| block_number | Option<u64> | Height of block from genesis. |
| slot | Option<u64> | Current slot. |
| tx_idx | Option<usize> | Transaction Index. |
| tx_hash | Option<String> | Transaction hash. |
Collateral Event
Data on collateral inputs.
| Name | DataType | Description |
|---|---|---|
| tx_id | String | Transaction ID. |
| index | u64 | Index of transaction input in inputs. |
Context
| Name | DataType | Description |
|---|---|---|
| block_number | Option<u64> | Height of block from genesis. |
| slot | Option<u64> | Current slot. |
| tx_idx | Option<usize> | Transaction Index. |
| tx_hash | Option<String> | Transaction hash. |
PlutusScriptRef Event
| Name | DataType | Description |
|---|---|---|
| data | String | .... |
Context
| Name | DataType | Description |
|---|---|---|
| block_number | Option<u64> | Height of block from genesis. |
| slot | Option<u64> | Current slot. |
| tx_idx | Option<usize> | Transaction Index. |
| tx_hash | Option<String> | Transaction hash. |
StakeRegistration Event
Data on stake registration event.
| Name | DataType | Description |
|---|---|---|
| credential | StakeCredential | Staking credentials. |
Context
| Name | DataType | Description |
|---|---|---|
| block_number | Option<u64> | Height of block from genesis. |
| slot | Option<u64> | Current slot. |
| tx_idx | Option<usize> | Transaction Index. |
| tx_hash | Option<String> | Transaction hash. |
StakeDeregistration Event
Data on stake deregistration event.
| Name | DataType | Description |
|---|---|---|
| credential | StakeCredential | Staking credentials. |
Context
| Name | DataType | Description |
|---|---|---|
| block_number | Option<u64> | Height of block from genesis. |
| slot | Option<u64> | Current slot. |
| tx_idx | Option<usize> | Transaction Index. |
| tx_hash | Option<String> | Transaction hash. |
StakeDelegation Event
Data on stake delegation event.
| Name | DataType | Description |
|---|---|---|
| credential | StakeCredential | Stake credentials. |
| pool_hash | String | Hash of stake pool ID. |
Context
| Name | DataType | Description |
|---|---|---|
| block_number | Option<u64> | Height of block from genesis. |
| slot | Option<u64> | Current slot. |
| tx_idx | Option<usize> | Transaction Index. |
| tx_hash | Option<String> | Transaction hash. |
PoolRegistration Event
Data on the stake registration event.
| Name | DataType | Description |
|---|---|---|
| operator | String | Stake pool operator ID. |
| vrf_keyhash | String | Kehash of node VRF operational key. |
| pledge | u64 | Stake pool pledge (lovelace). |
| cost | u64 | Operational costs per epoch (lovelace). |
| margin | f64 | Operator margin. |
| reward_account | String | Account to receive stake pool rewards. |
| pool_owners | Vec<String> | Stake pool owners. |
| relays | Vec<String> | .... |
| pool_metadata | Option<String> | .... |
Context
| Name | DataType | Description |
|---|---|---|
| block_number | Option<u64> | Height of block from genesis. |
| slot | Option<u64> | Current slot. |
| tx_idx | Option<usize> | Transaction Index. |
| tx_hash | Option<String> | Transaction hash. |
PoolRetirement Event
Data on stake pool retirement event.
| Name | DataType | Description |
|---|---|---|
| pool | String | Pool ID. |
| epoch | u64 | Current epoch. |
Context
| Name | DataType | Description |
|---|---|---|
| block_number | Option<u64> | Height of block from genesis. |
| slot | Option<u64> | Current slot. |
| tx_idx | Option<usize> | Transaction Index. |
| tx_hash | Option<String> | Transaction hash. |
GenesisKeyDelegation Event
Data on genesis key delegation.
Context
| Name | DataType | Description |
|---|---|---|
| block_number | Option<u64> | Height of block from genesis. |
| slot | Option<u64> | Current slot. |
| tx_idx | Option<usize> | Transaction Index. |
| tx_hash | Option<String> | Transaction hash. |
MoveInstantaneousRewardsCert Event
| Name | DataType | Description |
|---|---|---|
| from_reserves | bool | .... |
| from_treasury | bool | .... |
| to_stake_credentials | Option<BTreeMap<StakeCredential, i64>> | .... |
| to_other_pot | Option<u64> | .... |
Context
| Name | DataType | Description |
|---|---|---|
| block_number | Option<u64> | Height of block from genesis. |
| slot | Option<u64> | Blockchain slot. |
| tx_idx | Option<usize> | Transaction Index. |
| tx_hash | Option<String> | Transaction hash. |
Advanced Features
This section provides detailed information on the some of the advanced features available in Oura:
- Stateful Cursor: provides a mechanism to persist the "position" of the processing pipeline to make it resilient to restarts.
- Rollback Buffer: provides a way to mitigate the impact of chain rollbacks in downstream stages.
- Pipeline Metrics: allows operators to track the progress and performance of long-running Oura sessions.
- Mapper Options: A set of "expensive" event mapping procedures that require an explicit opt-in to be activated.
- Intersect Options: Advanced options for instructing Oura from which point in the chain to start reading from.
- Custom Network: Instructions on how to configure Oura for connecting to a custom network.
- Retry Policy: Instructions on how to configure retry policies for different operations
Stateful Cursor
The cursor feature provides a mechanism to persist the "position" of the processing pipeline to make it resilient to restarts.
Context
When running in daemon mode, a restart of the process will make Oura start crawling from the initially configured point. This default behavior can be problematic depending on the use-case of the operator.
An scenario where continuous "coverage" of all the processed blocks is important (eg: building a stateful view of the chain), it's prohibitive to have "gaps" while procesing. If Oura is configure to start from the "tip" of the chain, a restart of the process might miss some blocks during the bootstrap procedure.
A valid workaround to the above problem is to configure Oura to start from a fixed point in the chain. If a restart occurs, the pipeline will re-process the blocks, ensuring that each block was processed at least once. When working with sinks that implement idempotency when processing an event, receiving data from the same block multiple times should not impose a problem.
Although valid, the workaround described above is very inefficient. If the fixed point at which the pipeline starts is too far behind, catching up could take several hours, wasting time and resource.
Feature
Oura implements an optional stateful cursor that receives notifications from the sink stage of the pipeline to continuously track the current position of the chain. At certain checkpoints (every 10 secs by default), the position is persisted onto the file system at a configurable location.
Assuming that a restart occurs and the cursor feature is enabled, the process will attempt to locate and load the persisted value and instruct the source stage to begin reading chain data from the last known position.
Configuration
The cursor feature is a configurable setting available when running in daemon mode. A top level [cursor] section of the daemon toml file controls the feature:
[cursor]
type = "File"
path = "/var/oura/cursor"
[cursor]: The presence of this section in the toml file indicates Oura to enable the cursor feature.type: The type of persistence backend to use for storing the state of the cursor. The only available option at the moment isFile, which stores the cursor in the file system.path: The location of the cursor file within the file system. Default value isvar/oura/cursor.
Rollback Buffer
The "rollback buffer" feature provides a way to mitigate the impact of chain rollbacks in downstream stages of the data-processing pipeline.
Context
Handling rollbacks in a persistent storage requires clearing the orphaned data / blocks before adding new records. The complexity of this process may vary by concrete storage engine, but it always has an associated impact on performance. In some scenarios, it might even be prohibitive to process events without a reasonable level of confidence about the immutability of the record.
Rollbacks occur frequently under normal conditions, but the chances of a block becoming orphaned diminishes as the depth of the block increases. Some Oura use-cases may benefit from this property, some pipelines might prefer lesser rollback events, even if it means waiting for a certain number of confirmations.
Feature
Oura provides a "rollback buffer" that will hold blocks in memory until they reach a certain depth. Only blocks above a min depth threshold will be sent down the pipeline. If a rollback occurs and the intersection is within the scope of the buffer, the rollback operation will occur within memory, totally transparent to the subsequent stages of the pipeline.
If a rollback occurs and the intersection is outside of the scope of the buffer, Oura will fallback to the original behaviour and publish a RollbackEvent so that the "sink" stages may handle the rollback procedure manually.
Trade-off
There's an obvious trade-off to this approach: latency. A pipeline will not process any events until the buffer fills up. Once the initial wait is over, the throughput of the whole pipeline should be equivalent to having no buffer at all (due to Oura's "pipelining" nature). If a rollback occurs, an extra delay will be required to fill the buffer again.
Notice that even if the throughput isn't affected, the latency (measured as the delta between the timestamp at which the event reaches the "sink" stage and the original timestamp of the block) will always be affected by a fixed value proportional to the size of the buffer.
Implementation Details
The buffer logic is implemented in pallas-miniprotocols library. It works by keeping a VecDeque data structure of chain "points", where roll-forward operations accumulate at the end of the deque and retrieving confirmed points means popping from the front of the deque.
Configuration
The min depth is a configurable setting available when running in daemon mode. Higher min_depth values will lower the chances of experiencing a rollback event, at the cost of adding more latency. An node-to-node source stage config would look like this:
[source]
type = "N2N"
address = ["Tcp", "relays-new.cardano-mainnet.iohk.io:3001"]
magic = "mainnet"
min_depth = 6
Node-to-client sources provide an equivalent setting.
Pipeline Metrics
The metrics features allows operators to track the progress and performance of long-running Oura sessions.
Context
Some use-cases require Oura to be running either continuosuly or for prolonged periods of time. Keeping a sink updated in real-time requires 24/7 operation. Dumping historical chain-data from origin might take several hours.
These scenarios require an understanding of the internal state of the pipeline to facilitate monitoring and troubleshooting of the system. In a data-processing pipeline such as this, two important aspects need to observable: progress and performance.
Feature
Oura provides an optional /metrics HTTP endpoint that uses Prometheus format to expose real-time opertional metrics of the pipeline. Each stage (source / sink) is responsible for notifying their progress as they process each event. This notifications are then aggregated via counters & gauges and exposed via HTTP using the well-known Prometheus encoding.
The following metrics are available:
chain_tip: the last detected tip of the chain (height)rollback_count: number of rollback events occurredsource_current_slot: last slot processed by the source of the pipelinesource_current_height: last height (block #) processed by the source of the pipelinesource_event_count: number of events processed by the source of the pipelinesink_current_slot: last slot processed by the sink of the pipelinesink_event_count: number of events processed by the sink of the pipeline
Configuration
The metrics feature is a configurable setting available when running in daemon mode. A top level [metrics] section of the daemon toml file controls the feature:
# daemon.toml file
[metrics]
address = "0.0.0.0:9186"
endpoint = "/metrics"
[metrics]section needs to be present to enable the feature. Absence of the section will not expose any HTTP endpoints.address: The address at which the HTTP server will be listening for request. Expected format is<ip>:<port>. Use the IP value0.0.0.0to allow connections on any of the available IP address of the network interface. Default value is0.0.0.0:9186.endpoint: The path at which the metrics will be exposed. Default value is/metrics.
Usage
Once enabled, a quick method to check the metrics output is to navigate to the HTTP endpoint using any common browser. A local instance of Oura with metrics enabled on port 9186 can be accessed by opening the URL http://localhost:9186
An output similar to the following should be shown by the browser:
# HELP chain_tip the last detected tip of the chain (height)
# TYPE chain_tip gauge
chain_tip 6935733
# HELP rollback_count number of rollback events occurred
# TYPE rollback_count counter
rollback_count 1
# HELP sink_current_slot last slot processed by the sink of the pipeline
# TYPE sink_current_slot gauge
sink_current_slot 2839340
# HELP sink_event_count number of events processed by the sink of the pipeline
# TYPE sink_event_count counter
sink_event_count 2277714
# HELP source_current_height last height (block #) processed by the source of the pipeline
# TYPE source_current_height gauge
source_current_height 2837810
# HELP source_current_slot last slot processed by the source of the pipeline
# TYPE source_current_slot gauge
source_current_slot 2839340
# HELP source_event_count number of events processed by the source of the pipeline
# TYPE source_event_count counter
source_event_count 2277715
Regardless of the above mechanism, the inteded approach for tracking Oura's metrics is to use a monitoring infrastructure compatible with Prometheus format. Setting up and managing the monitoring stack is outside the scope of Oura. If you don't have any infrastructure in place, we recommend checking out some of the more commons stacks:
- Prometheus Server + Grafana
- Metricbeat + Elasticsearch + Kibana
- Telegraf + InfluxDB + Chronograf
The following screenshot is an example of a Grafana dashboard showing Prometheus data scraped from an Oura instance:
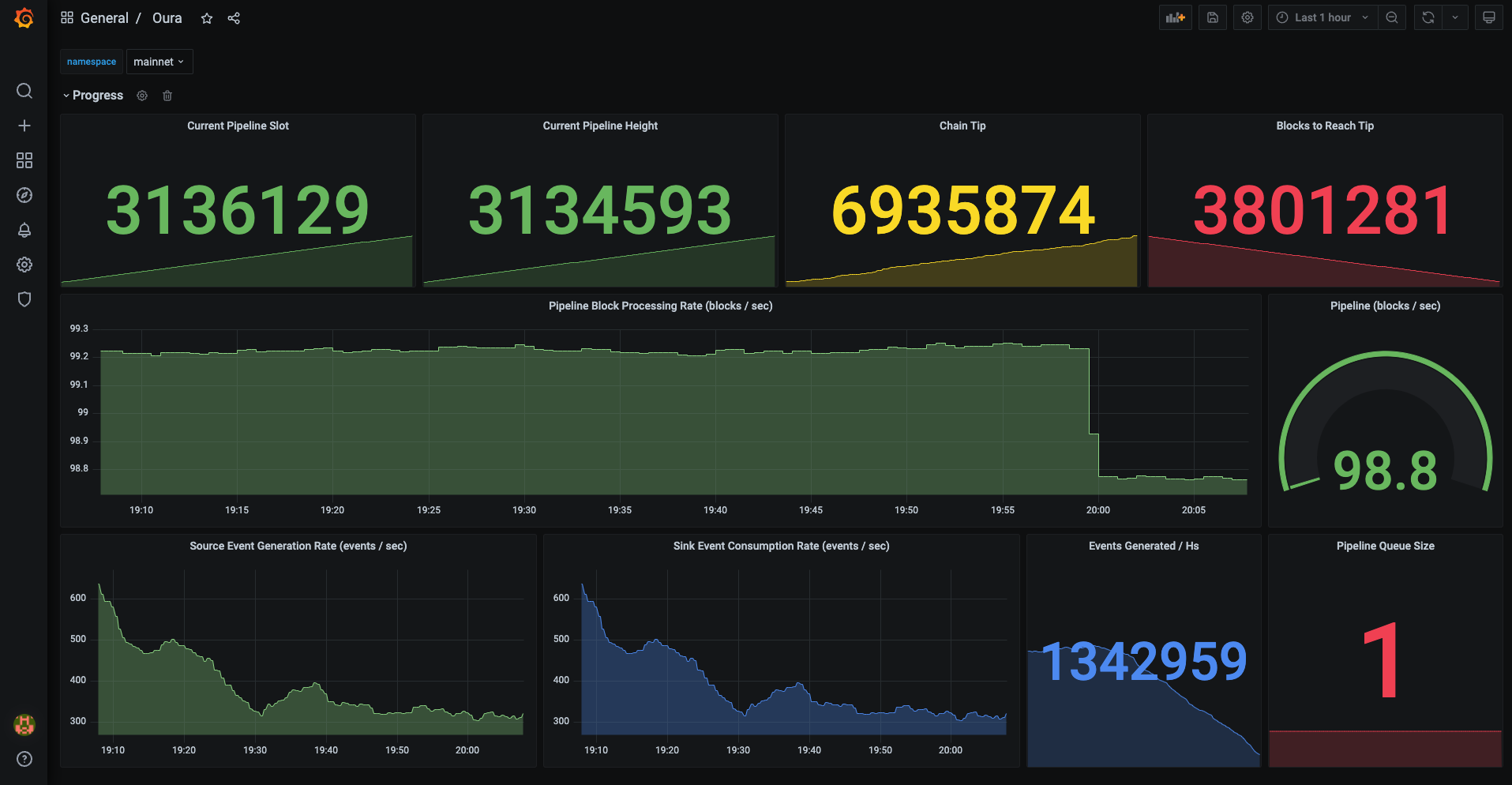
Mapper Options
A set of "expensive" event mapping procedures that require an explicit opt-in to be activated.
Context
One of the main concerns of Oura is turning block / tx data into atomic events to send down the pipeline for further processing. The source stage is responsible for executing these mapping procedures.
Most of the time, this logic is generic enough that it can be reused in different scenarios. For example, the N2N and the N2C sources share the same mapping procedures. If a particular use-case needs to cherry-pick, enrich or alter the data in some way, the recommendation is to handle the transformation in downstream stages, by using any of the built-in filter or by creating new ones.
There are some exceptions though, whenever a mapping has a heavy impact on performance, it is better to disable it completely at the source level to avoid paying the overhead associated with the initial processing of the data.
Feature
We consider a mapping procedure "expensive" if it involves: handling a relative large amount of data, computing some relatively expensive value or generating redundant data required only for very particular use cases.
For these expensive procedures, we provide configurable options that instructs an Oura instance running in daemon mode to opt-in on each particular rule.
Configuration
The mapper options can be defined by adding the following configuration in the daemon.toml file:
[source.mapper]
include_block_end_events = <bool>
include_transaction_details = <bool>
include_transaction_end_events = <bool>
include_block_cbor = <bool>
include_byron_ebb = <bool>
include_block_end_events: if enabled, the source will output an event signaling the end of a block, duplicating all of the data already sent in the corresponding block start event. Default value isfalse.include_transaction_details: if enabled, each transaction event payload will contain an nested version of all of the details of the transaction (inputs, outputs, mint, assets, metadata, etc). Useful when the pipeline needs to process the tx as a unit, instead of handling each sub-object as an independent event. Default value isfalse.include_transaction_end_events: if enabled, the source will output an event signaling the end of a transaction, duplicating all of the data already sent in the corresponding transaction start event. Defaul value isfalse.include_block_cbor: if enabled, the block event will include the raw, unaltered cbor content received from the node, formatted as an hex string. Useful when some custom cbor decoding is required. Default value isfalse.include_byron_ebb: if enabled, a block event will be emmitted for legacy epoch boundary block of the Byron era (deprecated in newer eras). Useful when performing validation on previous block hashes. Default value isfalse.
Intersect Options
Advanced options for instructing Oura from which point in the chain to start reading from.
Feature
When running in daemon mode, Oura provides 4 different strategies for finding the intersection point within the chain sync process.
Origin: Oura will start reading from the beginning of the chain.Tip: Oura will start reading from the current tip of the chain.Point: Oura will start reading from a particular point (slot, hash) in the chain. If the point is not found, the process will be terminated with a non-zero exit code.Fallbacks: Oura will start reading the first valid point within a set of alternative positions. If point is not valid, the process will fallback into the next available point in the list of options. If none of the points are valid, the process will be terminated with a non-zero exit code.
The default strategy use by Oura is Tip, unless an alternative option is specified via configuration.
You can also define a finalizing point by providing a block hash at which oura will stop reading from the the chain and exit gracefully.
Configuration
To modify the default behaviour used by the daemon mode, a section named [source.intersect] needs to be added in the daemon.toml file.
[source.intersect]
type = <Type>
value = <Value>
type: Defines which strategy to use. Valid values areOrigin,Tip,Point,Fallbacks. Default value isTip.value: Either a point or an array of points to be used as argument for the selected strategy.
If you'd like it to only sync an specific section of the chain, you can also instruct oura to stop syncing when it reaches an specific block hash by defining a [source.finalize] config:
[source.finalize]
until_hash = <BlockHash>
Note that unlike the intersect point, no slot is provided for the finalizer.
Examples
The following example show how to configure Oura to use a set of fallback intersection point. The chain sync process will attempt to first intersect at slot 4449598. If not found, it will continue with slot 43159 and finally with slot 0.
[source.intersect]
type = "Fallbacks"
value = [
[4449598, "2c9ba2611c5d636ecdb3077fde754413c9d6141c6288109922790e53bbb938b5"],
[43159, "f5d398d6f71a9578521b05c43a668b06b6103f94fcf8d844d4c0aa906704b7a6"],
[0, "f0f7892b5c333cffc4b3c4344de48af4cc63f55e44936196f365a9ef2244134f"],
]
This configuration will sync the whole Byron era only:
[source.intersect]
type = "Origin"
[source.finalize]
until_hash = "aa83acbf5904c0edfe4d79b3689d3d00fcfc553cf360fd2229b98d464c28e9de"
Custom networks
Instructions on how to configure Oura for connecting to a custom network (aka: other than mainnet / testnet).
Context
Oura requires certain information about the chain it is reading from. In a way, this is similar to the json config files required to run the Cardano node. These values are used for procedures such as encoding bech32 addresses, computing wall-clock time for blocks, etc.
Since mainnet and testnet are well-known, heavily used networks, Oura hardcodes these values as part of the binary release so that the user is spared from having to manually specify them. On the other hand, custom networks require the user to configure these values manually for Oura to establish a connection.
Feature
By adding a [chain] section in the daemon configuration file, users can provide the information required by Oura to connect to a custom network.
The [chain] section has the following propoerties:
| Name | DataType | Description |
|---|---|---|
| byron_epoch_length | integer | the length (in seconds) of a Byron epoch in this network |
| byron_slot_length | integer | the length (in seconds) of a Byron slot in this network |
| byron_known_slot | integer | the slot of a Byron block known to exist in this network |
| byron_known_hash | string | the hash of the known Byron block |
| byron_known_time | integer | the unix timestamp of the known Byron block |
| shelley_epoch_length | integer | the length (in seconds) of a Shelley epoch in this network |
| shelley_slot_length | integer | the length (in seconds) of a Shelley slot in this network |
| shelley_known_slot | integer | the slot of a Shelley block known to exist in this network |
| shelley_known_hash | String | the hash of the known Shelley block |
| shelley_known_time | integer | the unix timestamp of the known Shelley block |
| address_hrp | string | the human readable part for addresses of this network |
| adahandle_policy | string | the minting policy for AdaHandle on this network. |
Examples
Chain information for Testnet
This example configuration shows the values for Testnet. Since testnet values are hardcoded as part of Oura's release, users are not required to input these exact values anywhere, but it serves as a good example of what the configuration looks like.
[chain]
byron_epoch_length = 432000
byron_slot_length = 20
byron_known_slot = 0
byron_known_hash = "8f8602837f7c6f8b8867dd1cbc1842cf51a27eaed2c70ef48325d00f8efb320f"
byron_known_time = 1564010416
shelley_epoch_length = 432000
shelley_slot_length = 1
shelley_known_slot = 1598400
shelley_known_hash = "02b1c561715da9e540411123a6135ee319b02f60b9a11a603d3305556c04329f"
shelley_known_time = 1595967616
address_hrp = "addr_test"
adahandle_policy = "8d18d786e92776c824607fd8e193ec535c79dc61ea2405ddf3b09fe3"
Retry Policy
Advanced options for instructing Oura how to deal with failed attempts in certain sinks.
Supported Sinks
Configuration
To modify the default behaviour used by the sink, a section named [sink.retry_policy] needs to be added in the daemon.toml file.
[sink.retry_policy]
max_retries = 30
backoff_unit = 5000
backoff_factor = 2
max_backoff = 100000
max_retries: the max number of retries before failing the whole pipeline. Default value is20backoff_unit: the delay expressed in milliseconds between each retry. Default value is5000.backoff_factor: the amount to increase the backoff delay after each attempt. Default value is2.max_backoff: the longest possible delay in milliseconds. Default value is100000
Guides
Cardano => Kafka
This guide shows how to leverage Oura to stream data from a Cardano node into a Kafka topic.
About Kafka
Apache Kafka is a framework implementation of a software bus using stream-processing. It is an open-source software platform developed by the Apache Software Foundation written in Scala and Java.
Find more info about Kafka in wikipedia or visit Kafka's official website
Prerequisites
This examples assumes the following prerequisites:
- A running Cardano node locally accesible via a unix socket.
- A Kafka cluster accesible through the network.
- An already existing Kafka topic where to output events
- Oura binary release installed in local system
Instructions
1. Create an Oura configuration file cardano2kafka.toml
[source]
type = "N2C"
address = ["Unix", "/opt/cardano/cnode/sockets/node0.socket"]
magic = "testnet"
[sink]
type = "Kafka"
brokers = ["kafka-broker-0:9092"]
topic = "cardano-events"
Some comments regarding the above configuration:
- the
[source]section indicates Oura from where to pull chain data.- the
N2Csource type value tells Oura to get the data from a Cardano node using Node-to-Client mini-protocols (chain-sync instantiated to full blocks). - the
addressfield indicates that we should connect viaUnixsocket at the specified path. This value should match the location of your local node socket path. - the
magicfield indicates that our node is running in thetestnetnetwork. Change this value tomainnetif appropriate.
- the
- the
[sink]section tells Oura where to send the information it gathered.- the
Kafkasink type value indicates that Oura should use a Kafka producer client as the output - the
brokersfield indicates the location of the Kafka brokers within the network. Several hostname:port pairs can be added to the array for a "cluster" scenario. - the
topicfields indicates which Kafka topic to used for the outbound messages.
- the
2. Run Oura in daemon mode
Run the following command from your terminal to start the daemon process:
RUST_LOG=info oura daemon --config cardano2kafka.toml
You should see an output similar to the following:
[2021-12-13T22:16:43Z INFO oura::sources::n2n::setup] handshake output: Accepted(7, VersionData { network_magic: 764824073, initiator_and_responder_diffusion_mode: false })
[2021-12-13T22:16:43Z INFO oura::sources::n2n::setup] chain point query output: Some(Tip(Point(47867448, "f170baa5702c91b23580291c3a184195df7c77d3e1a03b3d6424793aacc850d6"), 6624258))
[2021-12-13T22:16:43Z INFO oura::sources::n2n::setup] node tip: Point(47867448,"f170baa5702c91b23580291c3a184195df7c77d3e1a03b3d6424793aacc850d6")
[2021-12-13T22:16:44Z INFO oura::sources::n2n] rolling block to point Point(47867448, "f170baa5702c91b23580291c3a184195df7c77d3e1a03b3d6424793aacc850d6")
[2021-12-13T22:16:52Z INFO oura::sources::n2n] requesting block fetch for point Some(Point(47867448, "f170baa5702c91b23580291c3a184195df7c77d3e1a03b3d6424793aacc850d6"))
[2021-12-13T22:17:15Z INFO oura::sources::n2n] requesting block fetch for point Some(Point(47867448, "f170baa5702c91b23580291c3a184195df7c77d3e1a03b3d6424793aacc850d6"))
[2021-12-13T22:17:20Z INFO oura::sources::n2n] requesting block fetch for point Some(Point(47867448, "f170baa5702c91b23580291c3a184195df7c77d3e1a03b3d6424793aacc850d6"))